1、梳理JML语言的理论基础、应用工具链情况
JML基础理论:
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言,基于Larch方法构建。JML可以为严格地程序设计提供一套行之有效的方法。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方法来检查代码实现对规格的满足情况。
从我个人的理解上,JML语言以简洁严谨的形式描述了代码规格要求,有利于代码的规格化设计,实现上层设计人员与底层实现人员的通信,保证对工程实现上的一致性。而对于我们而言,可以用工具来检查自己所写的代码是否符合课程要求,实现静态代码的检查。
JML注释结构:
块注释:/*@ annotation @*/
行注释://@annotation
JML表达式:
\result:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。
\old( expr )表达式:用来表示一个表达式 expr 在相应方法执行前的取值。
\not_modifified(x,y,...)表达式:与上面的\not_assigned表达式类似,该表达式限制括号中的变量在方法执行期间的取 值未发生变化。
\nonnullelements( container )表达式:表示 container 对象中存储的对象不会有 null
\type(type)表达式:返回类型type对应的类型(Class)
\typeof(expr)表达式:该表达式返回expr对应的准确类型。
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
方法规格:
前置条件:requires P;
后置条件:ensures P;
副作用范围限定:assignable、modifiable
signals子句与signals only子句
类型规格:
不变式invariant
状态变化约束constraint
JML应用工具链:
OpenJML:这是一个用于检查JML的工具,可以帮助我们检查自己编写的jml规格是否符合JML语法规则,是否具有正确且清晰的逻辑,防止错误的JML导致代码的错误。
JMLunitNG:是一个用于自动化检测代码的工具,可以根据JML规格自动生成测试代码TestNG来对代码进行检查,检查代码的实现是否正确,以及是否与JML的规格保持语义上的一致。
JMLUnit:可以根据JML规格自动生成单元测试代码,结合JMLunitNG可以对JML实现自动化检测。
关系:OpenJML可以检测我们所写的JML是否有基础的语法错误或者明显的逻辑不清,而JMLunit则可以根据JML自动生成测试代码,进而使用JMLunitNG就可以对改代码进行自动化测试,这三个工具配合使用可以保证JML的正确性。
2、部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例
部署完毕JMLUnitNG
使用的测试代码非常简陋,如下
执行jmlunitng工具得到所有的测试代码
随后对这些代码进行编译,得到了他们的.class文件
但此处问题出现了,我选择执行testng的时候却无论如何也执行不了,不知道是哪里出了问题
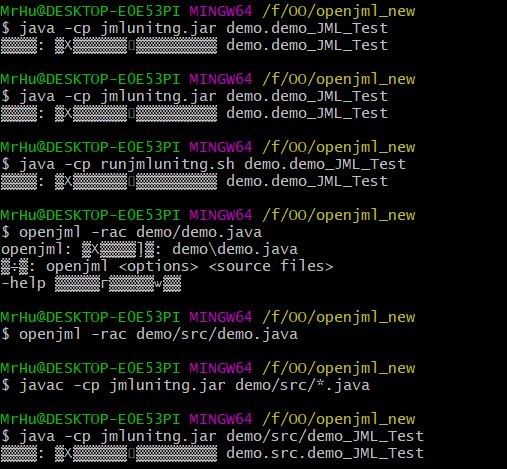
此次还是收获了很多,我会尽快在课下解决这个问题
3、代码结构
第一次作业:
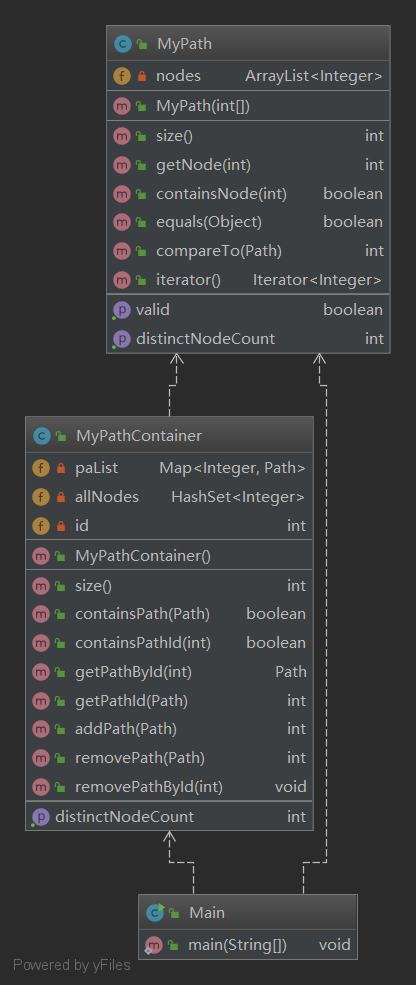
第一次作业的MyPath并没有什么难度,只需要严格遵守jml规格编写代码即可,问题是node是用什么数据结构,这里我用的是ArrayList,考虑到这里需要传迭代器而数组并没有现成的迭代器因此使用arraylist,其余均不难实现。
MyPathContainer的实现唯一可能爆复杂度的是distinctNodeCount这个函数,它需要数出所有path中不重复的node,我使用的数据结构是HashMap,这里我很惨地超时了,原因是我使用的方法是遍历所有的点数出不同的点,实际上后来发现使用HashSet在每次addPath的时候记录不同的点即可实现不超时的算法。
第二次作业
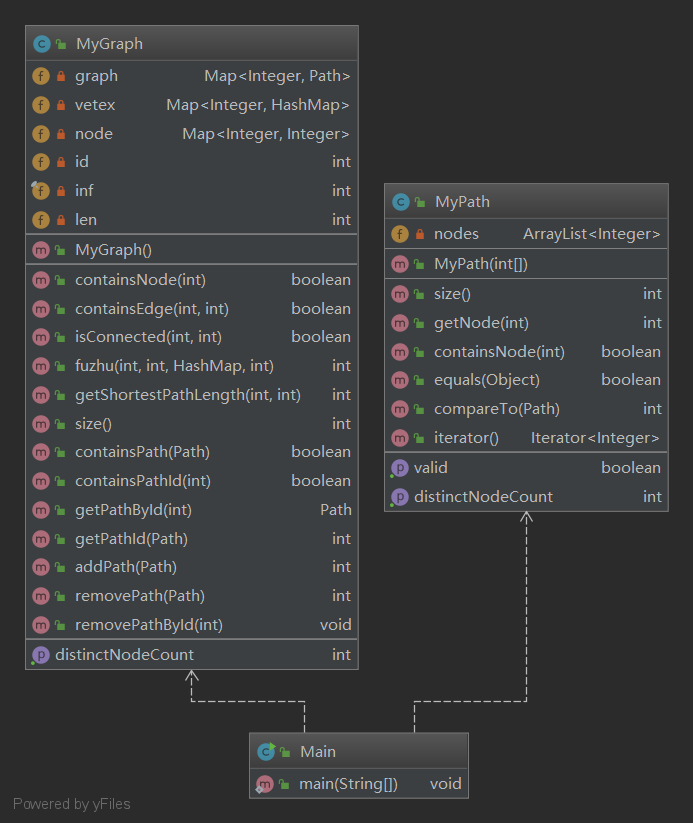
第二次作业的架构沿袭了第一次作业,MyPath的代码没有任何改动,在Graph中用HashMap嵌套HashMap实现了图的存储,实际上是记录了各个点之间的关系,实际使用的是邻接链表来存储图,最短路径我使用的是dfs,这里是这次作业的最大败笔,dfs实际上是深度优先的遍历算法,对于寻找最短路径并不合适,增加了时间复杂度,而实际上使用bfs即可解决,bfs平均找下来,最先找到的一条路径即是最短路径,显然在时间复杂度上会优于dfs
第三次作业

第三次作业我的实现思路是拆点,每个path读入的时候只要node首次出现在该path中就新建node,如果node已经在同一条path中出现多次则只创建一次这样保证了线内不算换乘,最低票价和最少不满意度基本上沿袭这个思路去写。
4、bug与修复:
本次出现的bug主要是在算法层面时间复杂度太高导致超时,而其他的bug只在第一次作业中出现,bug出在对于两个Integer类型的变量使用==判断相等,在将==改为equals之后bug即可得到修复,而这也让我对这一点十分深刻。
后面出现的bug在于dfs复杂度太高,应该使用bfs。
5、反思总结
本单元作业给我最深刻的感受并不在于算法如何设计,具体如何实现,而在于jml规格要求下如何去编写自己的架构,在开始的时候我是选择几乎完全翻译jml,死板地编写代码,但在不断的编写过程中发现自己初始的架构实际上并不适合后面的方法实现,我也认识到jml到代码的过程并不是翻译而是参考和尽可能契合地实现,这也就要求我们通读所有的方法jml规格结合类的规格后仍然要做出自己的架构规划,选择合适的数据结构,决定好算法大体如何实现。